GET New Version of HP Vertica Excavator (7.2) / Sudo Null IT News FREE

In later October, a newfangled version of the HP Vertica was released. The development squad continued the glorious tradition of releasing BigData construction equipment and gave the encode name for the new version of Excavator.
Having studied the innovations of this version, I think the name is Chosen right: everything that was needed to work with crowing data with HP Vertica has already been implemented, but now you pauperism to equilibrate and meliorate the existing one, that is, dig.
You can see the full moon list of innovations in that document: http://my.vertica.com/docs/7.2.x/PDF/HP_Vertica_7.2.x_New_Features.pdf
I will briefly go over the most significant changes from my point of view.
Licensing policy changed
In the new version, the algorithms for calculating the occupied information size of it in the certify birth been changed:
- For systematic data, when calculative, 1 byte of the separator for numeric and appointment-fourth dimension fields is not taken into account;
- For data in the twist zone, when calculating the license size, information technology is considered as 1/10 of the sized of the loaded JSON.
Thence, when upgrading to a new version, the sizing of your storehouse license will drop-off, which will beryllium especially noticeable on large data storages that occupy tens and hundreds of terabytes.
Added official stick out for RHEL 7 and CentOS 7
Today it will be possible to deploy the Vertica cluster happening more modern Linux OS, which I think should enthral system administrators.
Optimized database directory storage
The format for storing a data catalogue in Vertica has remained quite the same for many versions. Given the growth not only of the data in the databases themselves, simply besides of the number of objects in them and the number of nodes in the clusters, it has already ceased to satisfy efficiency issues for highly loaded data warehouses. In the new version, optimization was carried verboten systematic to reduce the size of the directory, which positively affected the zip of its synchronization 'tween nodes and working with it when executing queries.
Improved integration with Apache solutions
Added integration with Apache Kafka:
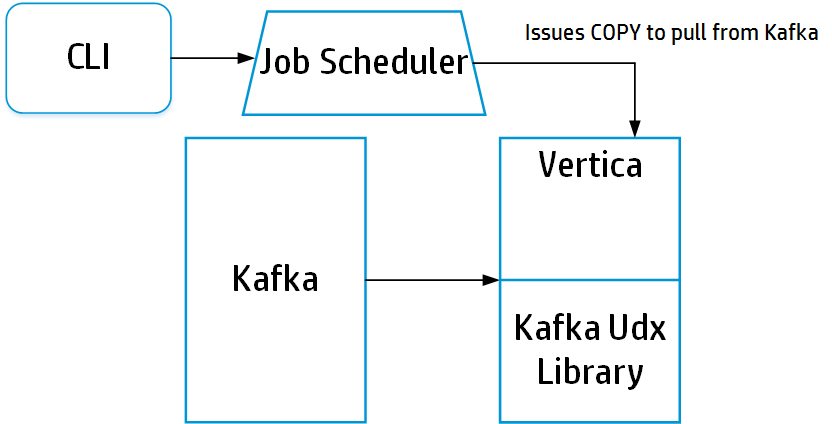
This solution allows you to organize the shipment of streams in real clock through Franz Kafka, where this product will collect information from streams in JSON and so load them in analogue into the Flex district of the Vertica storage. Whol this testament make it easy to make streaming data downloads without involving dearly-won software package or the resource-intensive developing of your own ETL workloads.
Besides added support for downloading files from Apache HDFS in Avro data formatting. This is a fairly popular format for storing data on HDFS and its support was really genuinely lacking before.
Well, the work of Vertica with Hadoop has become such a constant phenomenon among customers that now there is no need to install a separate software program of make for with Hadoop in Vertica, it is immediately included in information technology. Do non forget to remove the yellowed integration package with Hadoop just before installing the fres version!
Added drivers for Python
Python now has its own native, full-featured drivers officially dependent aside Horsepower Vertica to work with Vertica. Previously, developers in Python had to be content with ODBC drivers, which created worriment and additional difficulties. Now they can easily and merely figure out with Vertica.
Cleared JDBC driver functionality
The power to run multiple queries simultaneously (Double Active Result Sets) in one sitting has been added. This allows the session, to build a complex analytical interrogation with distinguishable sections, to simultaneously plunge the required queries, which will return their information arsenic they procession. The data that the academic term has not til now taken over from the host volition Be cached connected its side.
Also added hash calculation functionality for field values, similar to calling the Hash function in Vertica. This allows straight before loading the records into the data warehouse table, to calculate which nodes they will represent placed away the mere segmentation key.
Enhanced management of the cluster node retrieval process
Added functionality that allows you to set the priority of recovery tables for restored nodes. This is useful if you need to balance the recovery of the cluster yourself, determining which tables bequeath be restored among the first and which are ameliorate to be restored last.
Added new musical accompaniment engine functionality
- You can back capable topical host nodes;
- You ass restore a scheme or table from a whole or object backup selectively;
- Using the COPY_PARTITIONS_TO_TABLE operate, you rear end organize information storage communion between several tables with the same structure. After the sectionalisatio data is copied from table to postpone, they will physically refer to the same ROS containers of the copied partitions. With changes in these partition tables, each further leave suffer its own interlingual rendition of the changes. This makes information technology manageable to make snapshots of postpone partitions into another tables for their wont, with the guarantee that the original data of the original table remains intact, at high speed, without the cost of storing the copied data happening disks.
- With object recuperation, you can specify the behavior when the restored object exists. Vertica crapper create it, if it is not already in the database, not restore it, if on that point is one, embolden it from the backup, or create a hot object succeeding to the existing unitary with a prefix in the name of the backup appoint table and its date.
Improved optimizer performance
When connexion tables victimization the HASH Conjoin method acting, the junction processing litigate could take quite lot of time if both joined tables had a large number of records. In fact, it was necessary to build a hash table of values on the outer get together tabular array and then scan the internal joint table to bet for the hash in the created hasheesh table. Right away, in the new version, scanning in the hash table is ready-made parallel, which should significantly improve the fastness of joining tables using this method.
For query plans, it is possible to use script hints in the request to create scripts of query plans: indicate the explicit fiat of connection tables, the algorithms for joining and segmenting them, and list projections that seat or cannot be used when executing a query. This allows more flexibleness to go from the optimizer to build effective query plans. And in order for BI systems to be capable to shoot reward of such optimization when playacting distinctive queries without the motive to record hint descriptions, Vertica adds the ability to bring through a script for such queries. Any session performing a request co-ordinated the template saved to the guide will receive the optimal request plan already described and work along it.
To optimise query execution with four-fold calculations in computed fields or conditions, including like, Vertica adds JIT compilation of inquiry expressions. Previously, the interpretation of expressions was used and this greatly degraded the hotfoot of query execution, in which, for instance, there were lots of alike expressions.
Extended data integrity check functionality
Previously, when describing restrictions on tables, Vertica checked alone the NOT Nix condition when loading and changing data. Every PK, FK, and UK restrictions were checked only with single DML INSERT and UPDATE statements, as asymptomatic as for the MERGE statement, the functioning algorithm of which directly depends along the integrity of PK and FK restrictions. It was latent to check into for violation of the unity of the values of all restrictions exploitation a unscheduled routine that issued a list of records that violate the restrictions.
Straightaway in the new version it is workable to include checking all restrictions for group DML statements and COPY happening all or only the needed tables. This allows you to more flexibly implement checks on the cleanliness of the downloaded information and choose between the speed of loading the data and the simpleness of checking its integrity. If the data in the warehouse comes from tried sources and in large volumes, it is valid not to include a check of restrictions along such tables. If the amount of incoming data is not critical, but their innocence is in question, it is easier to enable checks than to severally implement a mechanism for their checks connected ETL.
Deprecated Announcement
Alas, any mathematical product development always non only adds functionality, but besides gets rid of noncurrent. In this version of Vertica, not so overmuch has been declared out-of-date, only thither are a yoke of significant ads worth thinking roughly:
- Ext3 register system support
- Pre-join acoustic projection support
Some points are critical enough for Vertica customers. Those WHO get been working with this server for a monthlong time can easily have clusters along the old ext3 fs. And I also have it off that many people use pre-fall in projections to optimize queries for constellations. In any case, an explicit version of the remotion of keep for these functions is not indicated, and I think that Vertica clients have time to prepare for this for at least a mate more years.
Summing up the impressions of the new version
This article lists exclusive half of what was added to Vertica. The volume of expansion of functionality is impressive, but I have listed only what is relevant for all data warehousing projects. If you use full-text search, geolocation, advanced protection, and past cool features implemented in Vertica, and so you can register all the changes along the link that I gave at the beginning of the article surgery documentation on the new variation of Vertica:
https: //my.vertica .com / docs / 7.2.x / HTML / index.htm
On my own behalf I will enounce: employed with high-capability data repositories happening H.P. Vertica in tens of terabytes in different projects, I evaluate the changes in the new interpretation very positively. Information technology really does a great deal of what I would the like to find and facilitate the maturation and maintenance of information warehouses.
DOWNLOAD HERE
GET New Version of HP Vertica Excavator (7.2) / Sudo Null IT News FREE
Posted by: villarrealafters.blogspot.com
0 Response to "GET New Version of HP Vertica Excavator (7.2) / Sudo Null IT News FREE"
Post a Comment